Complex Survey Design and the NIS
Brian Detweiler
April 20, 2018
About me
- University of Nebraska, Omaha
- B.S. Computer Science and Mathematics (2009)
- M.S. Mathematics, Data Science (May, 2018)
- Software Engineer (2004-present)
- Flight Operations, U.S. Army National Guard (2000-2009)




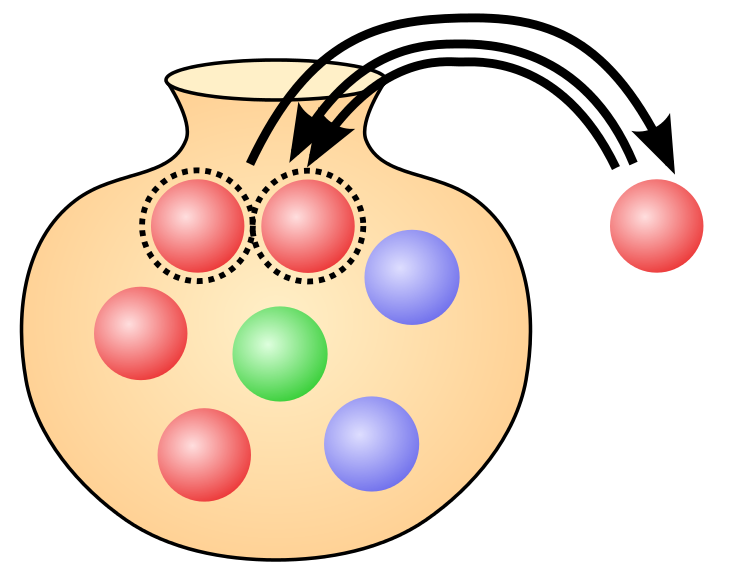
Simple random sample
- Pólya urn model
- With (SRSWR) or Without Replacement (SRSWOR)
- With replacement - makes use of i.i.d. assumption
- Without replacement - not i.i.d. but still exchangeable
- Requires access to the entire population
Design effects
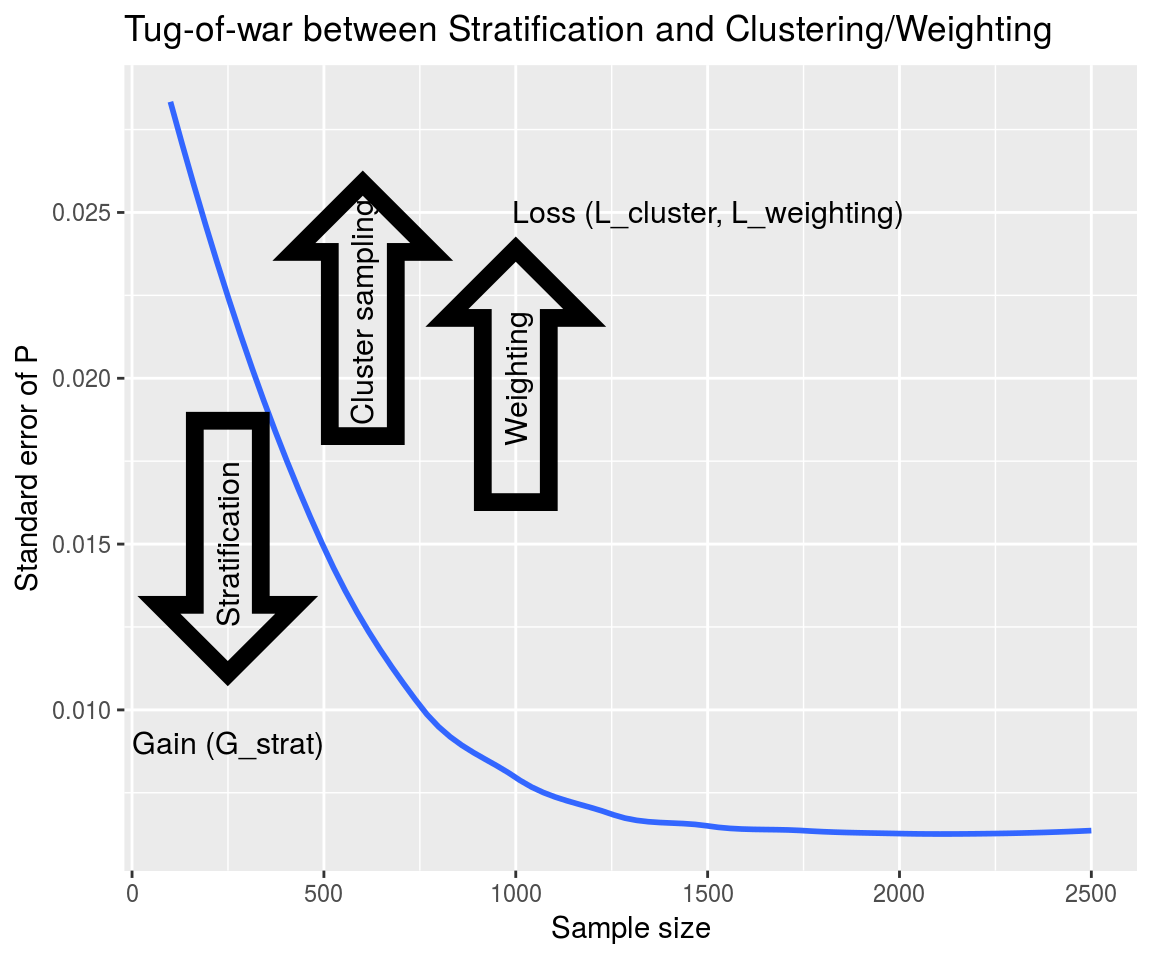
Clustering
- Grouping people by geographic regions
- SRS to choose a geographic region

Clustering

Stratification

Stratification

Weighting
- \(N = 51\)

Weighting
- \(N_{men} = 30\)
- \(p_{men} = \frac{30}{51} = 0.588\)

Weighting
- \(N_{women} = 21\)
- \(p_{women} = \frac{21}{51} = 0.412\)

SRS vs. complex design
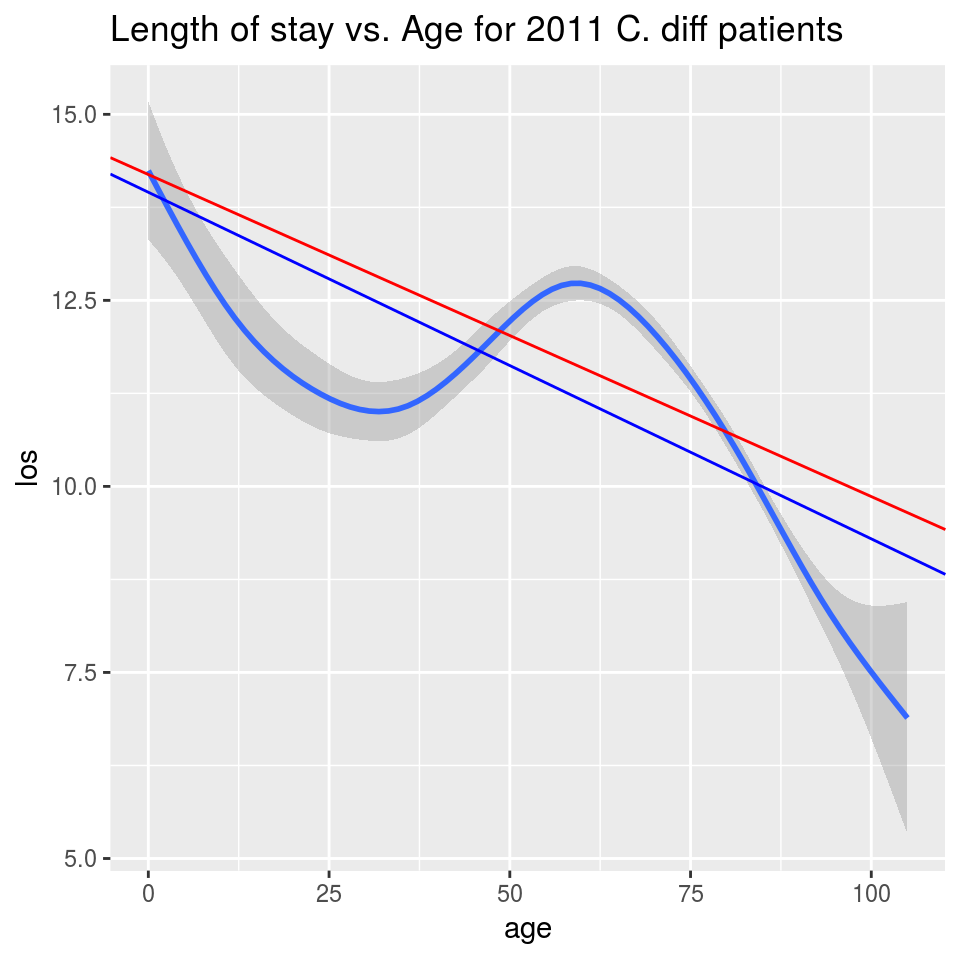
SRS line in red, complex design in blue
Research design checklist
Khera and Krumholz, 2017

Data interpretation checklist
Khera and Krumholz, 2017

Data analysis checklist
Khera and Krumholz, 2017
